* 본 글은 ChatGPT 공식 사이트와 각종 자료를 취합하여 이해한대로 작성해본 글입니다. 머신러닝 및 인공지능과 관련한 전문지식이 부족하므로 양해부탁드립니다.
잘못 기재된 내용이 있다면 댓글로 알려주세요:)
▶ ChatGPT란 무엇인가?
- 미국의 인공지능 연구소 Open AI가 개발한 대화기반 인공지능 챗봇
- Chat = 대화. GPT = Generated Pre-trained Transformer의 약어로 '미리 학습된 인공신경망'을 의미
이는 데이터를 학습시켜 문장을 생성해내는 ChatGPT의 원리를 담고 있음 - 기존 인공신경망 기술에 4,990억개의 데이터를 학습시켜 방대한 양의 데이터를 투입해 더 높은 완성도를 이끌어 낸 GPT-3에 새로운 강화학습 방법을 적용하여 업그레이드 한 GPT-3.5를 기반으로 개발된 프로그램
- 출시 후 2개월만에 활성 사용자 수 1억명을 달성하며 전세계적으로 큰 파장을 일으키고 있는 인공지능 기술
* Open AI는 전인류에 도움이 될 수 있는 '일반 인공 지능(Artificial General Intelligence)'을 개발하고 배포하는 것을 목적으로하는 인공지능 연구소로서 이번 ChatGPT 이외에도 이전 버전인 인공지능 언어모델 GPT-1, 2, 3과 이미지 생성 인공지능 DALL-E2, 다국어 음성인식 인공지능 Whisper 등 다양한 프로그램을 개발 중에 있음
▶ ChatGPT의 차별점?
문장생성에 특화되어 있는 생성 AI
- 간단한 질문에 대한 지식 제공의 답변부터 코딩 오류 찾기, 레포트나 시, 연애편지 작성까지 가능
- 대화형식으로 이루어지며 철학적인 질문에도 답변이 가능함
- 질문에 대해 해당 정보를 찾아 보여주는 단순 검색엔진의 범위를 넘어서 원하는 정보를 원하는 형태의 '결과물'로서 제공하는 '생성 AI'라는 점에서 큰 차별점이 있음
- 특히 문장 생성 및 언어에 특화된 인공지능 프로그램으로 결과물인 문장이나 글 구성과 연결성이 높은 수준을 보여 사람이 작성한 글과 구분이 잘 되지 않을 정도의 완성도를 보임
- 단순 정보 제공을 넘어서 이를 조합하여 새로운 결과물을 나타내면서 '구글의 시대는 끝났다'는 말이 나오기도 하였음
▶ ChatGPT의 원리?
- ChatGPT가 어떤 식으로 학습해서 완성도 높은 글을 작성할 수 있는 것인지, 그 원리에 대해 간단히 소개해 보고자 한다.
- 이 원리는 기본적으로 머신러닝 기법들에 기반하나, 작성자는 이에 대한 기초 지식이 매우 부족한 상태이므로 간단히 살펴보고 넘어가도록 하겠다
- ChatGPT는 기본적으로 머신러닝기법 중의 하나인 강화학습을 통해 훈련됨
- 강화학습: 기계 학습의 대상이 되는 컴퓨터 프로그램이 주어진 상태에서 최적의 행동을 선택할 수 있도록 행동의 결과가 좋았는지 나빴는지 알려주는 보상 혹은 강화(Reinforcement)의 과정을 거치는 머신러닝 기법
- 특히 사람의 피드백을 통한 강화학습 방법인 RLHF(Reinforcement Learning from Human Feedback)를 적용하여 부정확한 답변이나 유해한 답변을 감소시킬 수 있었음
- 다음은 전반적인 훈련 과정을 도식화한 그림과 함께 살펴봄
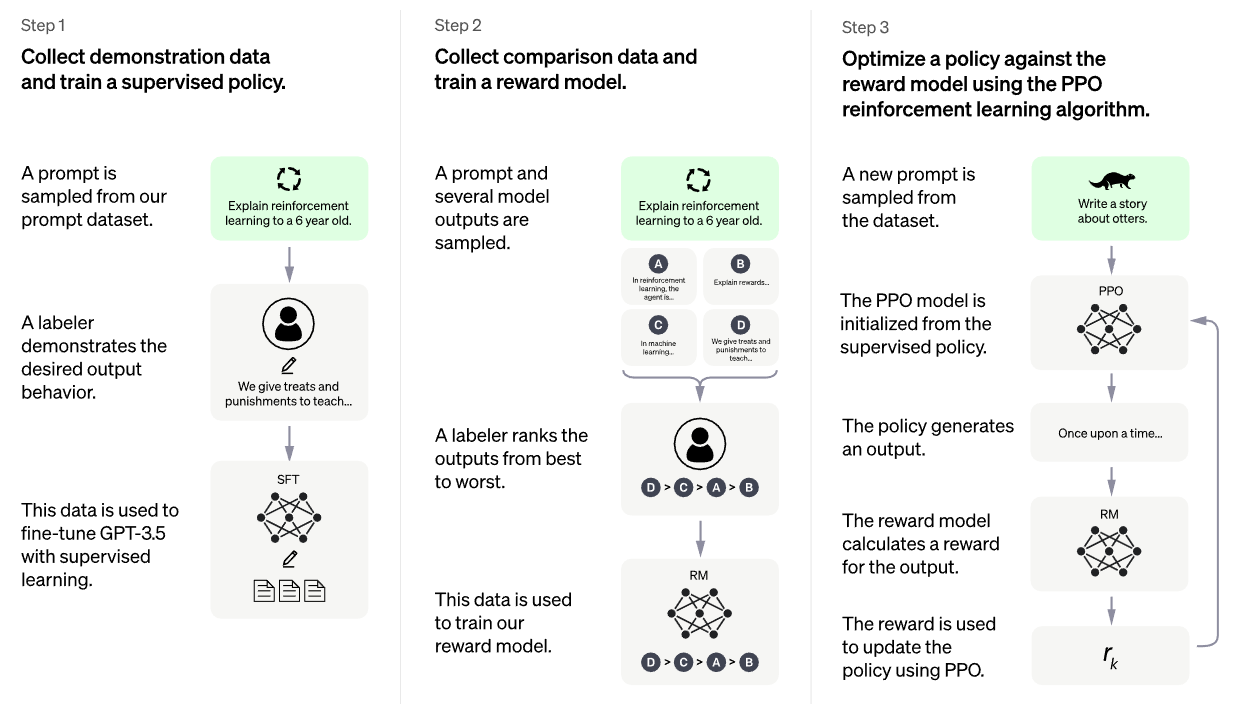
Step 1. 데모데이터 수집 및 조정된 정책 훈련
*정책 Policy: 강화학습에서 학습 대상이 되는 기계 및 프로그램이 주어진 상태에서 어떤 행동을 취할지 표현하는 것
- 프롬프트(일종의 '질문'이라고 이해하면 쉬움) 데이터 셋에서 샘플 프롬프트를 도출
- AI 트레이너는 이에 대한 이상적인 출력 결과(답변)를 보여줌 ☞ 이 과정이 RLHF 과정
→ AI 트레이너는 사용자의 질문을 입력하고, AI의 답변을 완성도 높은 대화로 구성하는 작업을 거치면서 양쪽 모두의 대화 과정을 구성하고 이 대화 데이터 셋을 학습을 위해 넘겨줌 - 이 데이터는 지도학습을 통해 GPT-3.5를 미세 조정(Fine tuning)하는 과정에 사용됨
*Fine tuning이란? 이미 학습된 모델의 초기값들을 여러 방향으로 바꿔가면서 적합한 모델을 학습해 나가는 과정과 방식.
학습이 완료된 모델에 적은 양의 데이터로 목적에 맞는 학습을 하는 전이학습(Transfer Learning)을 위한 과정 중 하나
Step2. 비교 데이터 수집 및 Reward Model(보상 모델) 훈련
- AI 트레이너가 챗봇과 대화한 데이터와 답변한 메시지들을 무작위로 샘플링(비교 데이터)
- AI 트레이너는 A,B,C,D 여러가지 출력 답변 샘플들의 질적 순위를 매김
- 이 순위 데이터는 보상 모델(Reward model) 학습에 사용 됨
Step3. PPO 기법을 활용하여 보상 모델의 정책(Policy) 최적화
- PPO(Proximal Policy Optimization) 근사 정책 최적화: 응답이 생성될 때 마다 모델의 정책을 업데이트하는데 사용되며 보상 모델이 과도하게 최적화되어 사람의 기존 의도와 멀어지는 것을 방지하기 위하여 사용됨
- PPO 기법은 앞서 지도학습된 정책에 우선 적용되어 하나의 프롬프트(질문)에 대한 답변을 생성하며 앞선 보상모델은 이 답변에 대한 보상을 계산하여 출력
- 이 계산된 보상은 다시 PPO 기법을 활용하여 정책을 최적화하고 업데이트하는데 사용
본 글에서는 ChatGPT에 대한 기본적인 정보와 이론에 대해서 간단하게 훑어 보았다.
이어지는 다음 글 "ChatGPT 맛보기(2): ChatGPT 사용하기"에서는 실제로 ChatGPT를 작동시켜보는 과정을 함께 살펴보도록 하겠다.
*내용 참고
Opne AI 공식 사이트 https://openai.com/blog/chatgpt/
네이버 지식백과, 챗GPT https://terms.naver.com/entry.naver?docId=6646863&cid=43667&categoryId=43667
네이버 지식백과, 강화형 기계 학습 https://terms.naver.com/entry.naver?docId=5917551&cid=66682&categoryId=66682
유튜브 차이나는 클라스 강연 https://www.youtube.com/watch?v=OktEGBDholo
네이버 블로그, Fine tuning의 개념 https://blog.naver.com/ssj860520/222837615143
'Tips' 카테고리의 다른 글
| [GIS 해보기] 데이터 검색 및 수집 (0) | 2023.03.14 |
|---|---|
| ChatGPT 맛보기(2): ChatGPT 사용하기 (0) | 2023.02.22 |
| [다층모형] 2. 다층모형 분석 기본원리 (0) | 2023.02.20 |
| [다층모형] 1. 다층모형 개론 (0) | 2023.02.20 |
| 시스템다이내믹스 with Vensim - (1) 소개 (0) | 2023.02.09 |



댓글